Getting Started¶
How to run a cluster?¶
- To run a simple cluster you need:
- a cluster definition file;
- access to a cloud (or bare-metal cluster);
- the Karamel client application.
You can use Karamel as a standalone application with a Web UI or embed Karamel as a library in your application, using the Java-API to start your cluster.
Linux/Mac¶
1. Starting Karamel
To run Karamel, download the Linux/Mac binaries from http://www.karamel.io. You first have to unzip the binaries (
tar -xf karamel-0.2.tgz). From your machine’s terminal (command-line), run the following commands:cd karamel-0.2 ./bin/karamelThis should open a window on your Web Browser if it is already open or open your default Web Browswer if one is not already open. Karamel will appear on the webpage opened.
Windows¶
1. Starting Karamel
To run Karamel, download the Windows binaries from http://www.karamel.io. You first have to unzip the binaries. From Windows Explorer, navigate to the folder karamel-0.2 (probably in the Downloads folder) and double-click on karamel.exe file to start Karamel.
Karamel Homepage. Click on
Menuto load a Cluster Definition file.
2. Customize and launch your cluster Take a look into the Board-UI.
Command-Line in Linux/Mac¶
You can either set environment variables containing your EC2 credentials or enter them from the console. We recommend you set the environment variables, as shown below.
export AWS_KEY=... export AWS_SECRET_KEY=... ./bin/karamel -launch examples/hadoop.yml
After you launch a cluster from the command-line, the client loops, printing out to stdout the status of the install DAG of Chef recipes every 20 seconds or so. Both the GUI and command-line launchers print out stdout and stderr to log files that can be found from the current working directory in:
tail -f log/karamel.log
Java-API:¶
You can run your cluster in your Java program by using our API.
- 1. Jar-file dependency
First add a dependency into the karamel-core jar-file, its pom file dependency is as following:
<dependency> <groupId>se.kth</groupId> <artifactId>karamel-core</artifactId> <scope>compile</scope> </dependency>
- 2. Karamel Java API
Load the content of your cluster definition into a variable and call KaramelApi like this example:
//instantiate the API KaramelApi api = new KaramelApiImpl(); //load your cluster definition into a java variable String clusterDefinition = ...; //The API works with json, convert the cluster-definition into json String json = api.yamlToJson(ymlString); //Make sure your ssh keys are available, if not let API generate it for SshKeyPair sshKeys = api.loadSshKeysIfExist(""); if (sshKeys == null) { sshKeys = api.generateSshKeysAndUpdateConf(clusterName); } //Register your ssh keys, thats the way of confirming your ssh-keys api.registerSshKeys(sshKeys); //Check if your credentials for AWS (or any other cloud) already exist otherwise register them Ec2Credentials credentials = api.loadEc2CredentialsIfExist(); api.updateEc2CredentialsIfValid(credentials); //Now you can start your cluster by giving json representation of your cluster api.startCluster(json); //You can always check status of your cluster by running the "status" command through the API //Run status in some time-intervals to see updates for your cluster long ms1 = System.currentTimeMillis(); int mins = 0; while (ms1 + 24 * 60 * 60 * 1000 > System.currentTimeMillis()) { mins++; System.out.println(api.processCommand("status").getResult()); Thread.currentThread().sleep(60000); }
This code block will print out your cluster status to the console every minute.
Launching an Apache Hadoop Cluster with Karamel¶
A cluster definition file is shown below that defines a Apache Hadoop V2 cluster to be launched on AWS/EC2. If you click on Menu->Load Cluster Definition and open this file, you can then proceed to launch this Hadoop cluster by entering your AWS credentials and selecting or generating an Open Ssh keypair.
The cluster defintion includes a cookbook called ‘hadoop’, and recipes for HDFS’ NameNode (nn) and DataNodes (dn), as well as YARN’s ResourceManager (rm) and NodeManagers (nm) and finally a recipe for the MapReduce JobHistoryService (jhs). The nn, rm, and jhs recipes are included in a single group called ‘metadata’ group, and a single node will be created (size: 1) on which all three services will be installed and configured. On a second group (the datanodes group), dn and nm services will be installed and configured. They will will be installed on two nodes (size: 2). If you want more instances of a particular group, you simply increase the value of the size attribute, (e.g., set “size: 100” for the datanodes group if you want 100 data nodes and resource managers for Hadoop). Finally, we parameterize this cluster deployment with version 2.7.1 of Hadoop (attr -> hadoop -> version). The attrs section is used to supply parameters that are fed to chef recipes during installation.
name: ApacheHadoopV2
ec2:
type: m3.medium
region: eu-west-1
cookbooks:
hadoop:
github: "hopshadoop/apache-hadoop-chef"
version: "v0.1"
attrs:
hadoop:
version: 2.7.1
groups:
metadata:
size: 1
recipes:
- hadoop::nn
- hadoop::rm
- hadoop::jhs
datanodes:
size: 2
recipes:
- hadoop::dn
- hadoop::nm
The cluster definition file also includes a cookbooks section. Github is our artifact server. We only support the use of cookbooks in our cluster definition file that are located on GitHub. Dependent cookbooks (through Berkshelf) may also be used (from Opscode’s repository, Chef supermarket or GitHub), but the cookbooks referenced in the YAML file must be hosted on GitHub. The reason for this is that the Karamel runtime uses Github APIs to query cookbooks for configuration parameters, available recipes, dependencies (Berksfile) and orchestration rules (defined in a Karamelfile). The set of all Karamelfiles for all services is used to build a directed-acyclic graph (DAG) of the installation order for recipes. This allows for modular development and automatic composition of cookbooks into cluster, where each cookbook encapsulates its own orchestration rules. In this way, deployment modules for complicated distributed systems can be developed and tested incrementally, where each service defines its own independent deployment model in Chef and Karamel, and independet deployment modules can be automatically composed into clusters in cluster definition files. This approach supports an incremental test and development model, helping improve the quality of deployment software.
Designing an experiment with Karamel/Chef¶
An experiment in Karamel is a cluster definition file that contains a recipe defining the experiment. As such, an experiment requires a Chef cookbook and recipe, and writing Chef cookbooks and recipes can be a daunting prospect for even experienced developers. Luckily, Karamel provides a UI that can take a bash script or a python program and generate a karamelized Chef cookbook with a Chef recipe for the experiment. The Chef cookbook is automatically uploaded to a GitHub repository that Karamel creates for you. You recipe may have dependencies on other recipes. For example, a MapReduce experiment defined on the above cluster should wait until all the other services have started before it runs. On examination of the Karamelfile for the hadoop cookbook, we can see that hadoop::jhs and hadoop::nm are the last services to start. Our MapReduce experiment can state in the Karamelfile that it should start after the hadoop::jhs and hadoop::nm services have started at all nodes in the cluster.
Experiments also have parameters and produce results. Karamel provides UI support for users to enter parameter values in the Configure menu item. An experiment can also download experiment results to your desktop (the Karamel client) by writing to the filename /tmp/<cookbook>__<recipe>.out. For detailed information on how to design experiments, go to experiment designer
Designing an Experiment: MapReduce Wordcount¶
This experiment is a wordcount program for MapReduce that takes as a parameter an input textfile as a URL. The program counts the number of occurances of each word found in the input file.
First, create a new experiment called mapred in GitHub (any organization). You will then need to click on the advanced tickbox to allow us to specify dependencies and parameters.
.. We keep them separate experiments to measure their time individually.
user=mapred group=mapred textfile=http://www.gutenberg.org/cache/epub/1787/pg1787.txt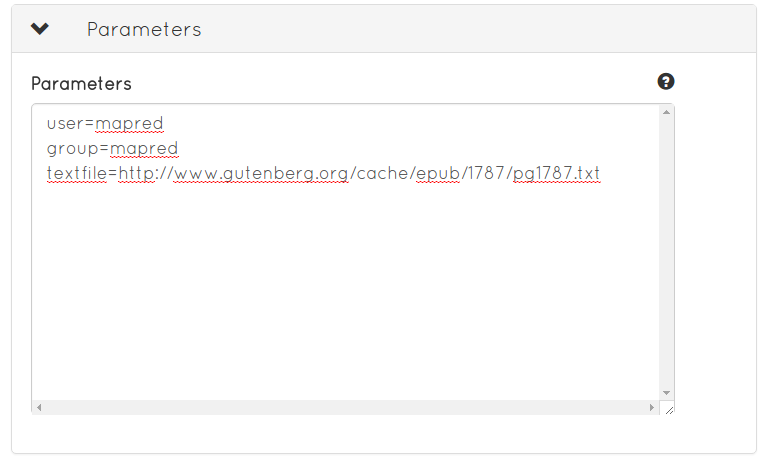
Defining the texfile input parameter. Parameters are key-value pairs defined in the Parameter box.
The code generator bash script must wait until all HDFS datanodes and YARN nodemanagers are up and running before it is run. To indicate this, we add the following lines to Dependent Recipes textbox:
hadoop::dn hadoop::nm
Our new cookbook will be dependent on the hadoop cookbook, and we have to enter into the Cookbook Dependencies textbox the relative path to the cookbook on GitHub:
cookbook 'hadoop', github: 'hopshadoop/apache-hadoop-chef'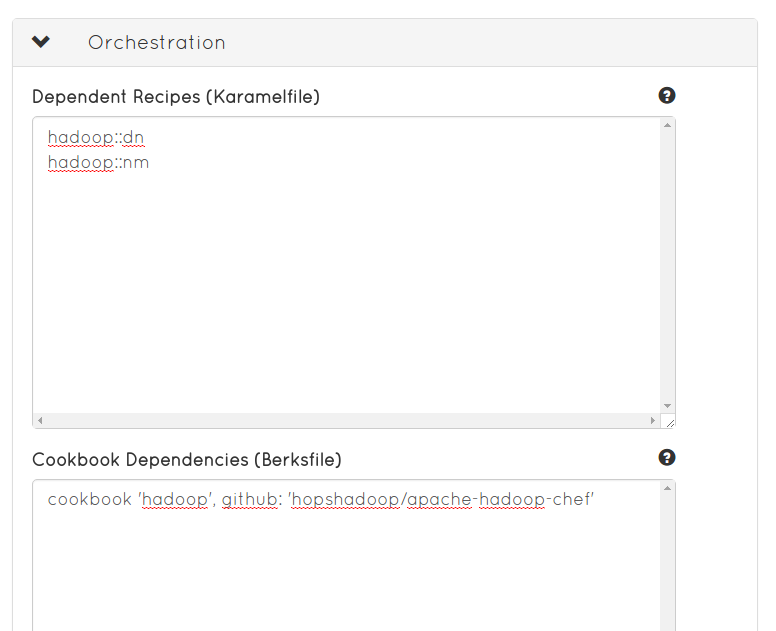
Define the Chef
cookbook dependenciesas well as thedependent recipes, the recipes that have to start before the experiments in this cookbook.
The following code snippet runs MapReduce wordcount on the input parameter textfile. The parameter is referenced in the bash script as #{node.mapred.textfile}, which is a combination of node.``<cookbookname>``.``<parameter>``.